
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- hadoop
- 빅데이터
- Namenode
- execution_date
- Windows
- SlackWebhookOperator
- MapReduce
- slack app
- docker
- yarn
- java
- Service
- python
- jupyter
- slack
- Scala
- LDAP
- 람다 아키텍처
- 정규표현식
- airflow
- HIVE
- HDFS
- Example DAG
- Kafka
- re
- NoSQL
- HDP
- Lambda architecture
- HBase
- ambari
- Today
- Total
IT 삽질기
sqoop이란 ? 본문
sqoop이란?
sqoop은 일반적으로 사용하는 RDBMS(MySQL, Oracle)와 HDFS(Hive, HBase)간 데이터를 전송하기 위해 사용하는 툴로
HDFS 저장소를 기준으로 import(RDBMS -> HDFS), export(HDFS -> RDBMS) 기능을 제공하며, MapReduce방식으로 동작한다. 특별한 설정이 없는 경우 text file형식으로 HDFS에 적재되지만, 설정을 통해 sequence file, avro, parquet에 대한 형식을 지원한다.
여기서는 sqoop의 import와 export에 대해서 알아보도록 하자
Sqoop import
먼저 sqoop import 과정에 대해 알아보자.
sqoop import는 아래와 같이 동작한다.

순서에 따라 살펴보도록 하자.
(1) sqoop명령어가 실행되면 sqoop client는 RDBMS에서 메타데이터(column, data type)를 가지고 온다. 이 때 RDBMS에서 사용하는 data type과 HDFS에서 사용하는 data type이 자동으로 매핑된다.
(2) 메타데이터를 기반으로 하여 테이블 특화 java class를 생성하는데, 생성된 클래스를 이용하여 map task가 진행된다.
(3) map task에 명령을 전달하여 RDBMS 데이터를 HDFS에 이관하는 작업을 진행하게 되는데, 분할 기준 컬럼을 통해 자동으로 분할되어 동작하며, 좀 더 효율적인 작업을 위해서는 --split-by 옵션을 이용하여 직접 설정할 수 있다.
sqoop import과정에서는 map과정만 필요할 뿐 reduce과정은 필요하지 않으며, 데이터가 정상적으로 변환되는 경우 HDFS상에서 확인이 가능하다.
Hive로 데이터를 이관하는 경우 테이블이 존재하지 않을 때 생성된 java class를 이용하여 hive table를 만든 후 데이터를 이관하는 옵션이 존재 --hive-import
Sqoop export
다음으로 export 과정에 대해서 알아보도록 하자.
export 과정은 import와 반대로 HDFS 시스템에 있는 데이터를 RDBMS로 이관시키는 작업인데, import와 거의 비슷한 과정을 거친다.
export 과정은 아래와 같다.
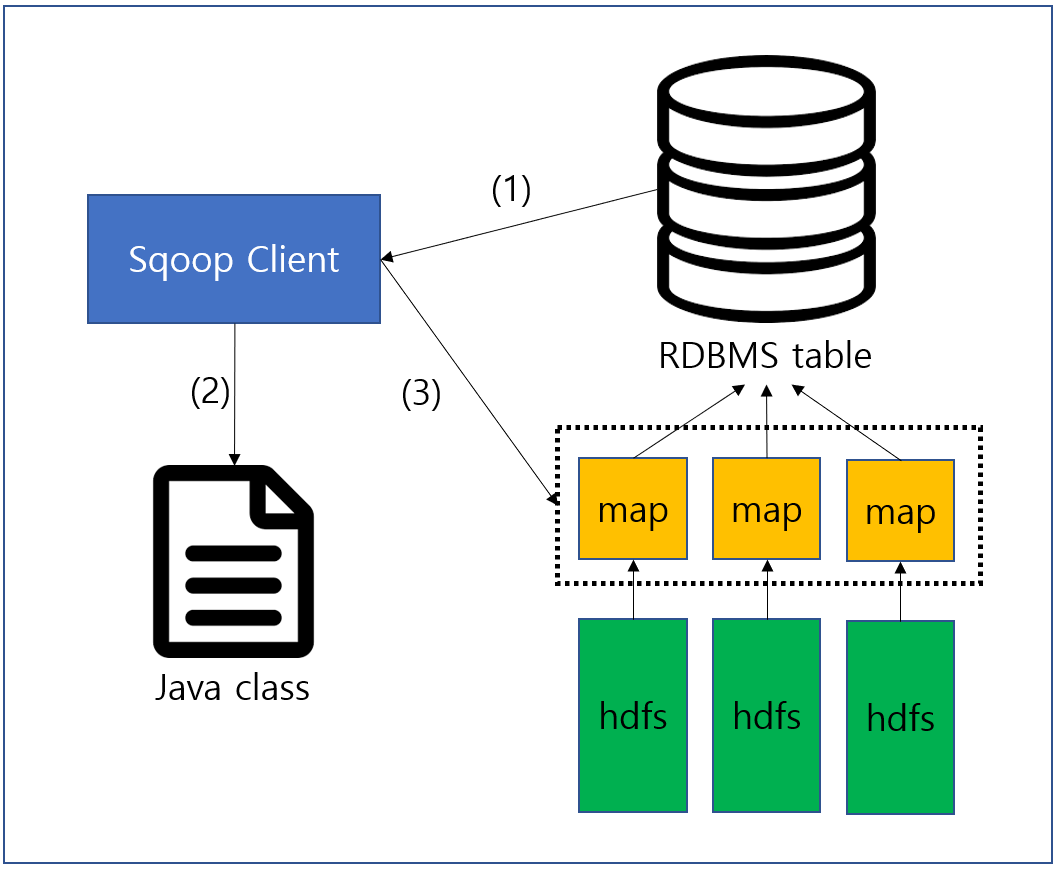
동작은 거의 비슷하나 주의해야할 부분이 있다.
(1) 메타데이터를 가지고 오는 주체가 RDBMS라는 부분인데, import와 동일하게 RDBMS의 메타 데이터를 이용하여 (2) java class를 생성한다. 이는 HDFS(Hive)에서 사용하는 자료형과 RDBMS에서 사용하는 자료형의 매핑이 정확하게 이루어지지 않을 경우가 발생할 수 있기 때문인데, 이로 인해 export 과정에서는 꼭 RDBMS에 target table를 미리 준비해두어야 한다.
나머지 과정은 비슷하지만 순서대로 살펴보도록 하자.
(1) RDBMS의 table에서 메타데이터를 가지고 온다.
(2) 메타 데이터를 이용하여 table 특화 java class를 생성한다.
(3) 생성된 java class를 이용하여 map task에 전달하고 map task에서는 이를 이용하여 RDBMS table에 insert문을 이용하여 데이터를 적재한다.
참고자료
'BigData' 카테고리의 다른 글
| 람다 아키텍처(lambda-architecture)란? (0) | 2021.08.23 |
|---|---|
| Kudu란? (0) | 2021.05.08 |
| 빅데이터 처리 과정 (0) | 2020.12.18 |
| 빅데이터의 정의 (0) | 2020.06.24 |
| Nifi에서 Hive3 연결하기 (0) | 2020.03.31 |


